Что всё это значит?
Оригинал: http://diveintohtml5.info/semantics.html
Перевод: Влад Мержевич
В этой главе мы возьмем веб-страницу и, не делая с ней ничего плохого, улучшим ее. Местами она станет короче, местами длиннее, но она станет семантической. Возрадуемся!
Вот пример страницы. Откройте ее в новой вкладке и не возвращайтесь, пока не посмотрите ее исходный код по меньшей мере один раз.
Доктайп
Посмотрите на первую строку нашего кода.
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
Она называется доктайп. Это длинная история с черной магией, стоящая за доктайпом. Во время работы над Internet Explorer 5 под Mac его разработчики столкнулись с неожиданной проблемой. Новая версия этого браузера содержала столько улучшений по части стандартов, что старые страницы отображались некорректно. Вернее, отображались они надлежащим образом, по спецификации, но люди считали, что отображаются они неправильно. Авторы страниц при верстке ориентировались на доминирующие браузеры того времени — Netscape 4 и Internet Explorer 4. Браузер IE5/Mac был настолько передовым, что фактически разрушил Сеть.
В Майкрософте пришли к оригинальному решению. Перед отображением страницы, IE5/Mac смотрит на доктайп, который, как правило, стоит в первой строке кода (еще до элемента <html>). Старые страницы, которые ориентировались на «причуды» старых браузеров, обычно не имеют доктайпа, поэтому IE5/Mac отображал их подобно этим браузерам. Для включения поддержки новых стандартов, авторы страниц должны были вставить <!DOCTYPE> перед <html>.
Эта идея распространилась как лесной пожар и вскоре все основные браузеры имели два режима: «режим совместимости» и «стандартный режим». Конечно, вскоре все это вышло из-под контроля. Когда Mozilla запустила версию 1.1 своего браузера, она обнаружила, что страницы, которые отображаются в «стандартном режиме» в действительности основываются на одной конкретной причуде под именем доктайп. Mozilla подправила свой браузерный движок для устранения этого недостатка и тысячи страниц рассыпались в один миг. Таким образом был создан, и я не выдумываю это, «почти стандартный режим».
В своей основной работе Переключение режимов браузера через доктайп Хенри Сивонен выделил следующие режимы.
Режим совместимости
В режиме совместимости браузеры нарушают современные веб-спецификации и чтобы избежать «рассыпания» страниц отображают их в соответствии с практикой, распространенной в конце 90-х годов.
Стандартный режим
В стандартном режиме браузеры пытаются вывести документы в соответствии со спецификацией в той мере, насколько она реализована в браузере. В HTML5 называется «не режим совместимости».
Почти стандартный режим
Браузеры Firefox, Safari, Chrome, Opera (начиная с 7.5) и IE8 также поддерживают почти стандартный режим, в котором вертикальные размеры ячеек таблиц реализуются традиционно, а не в полном соответствии со спецификацией CSS2. В HTML5 называется «ограниченный режим совместимости».
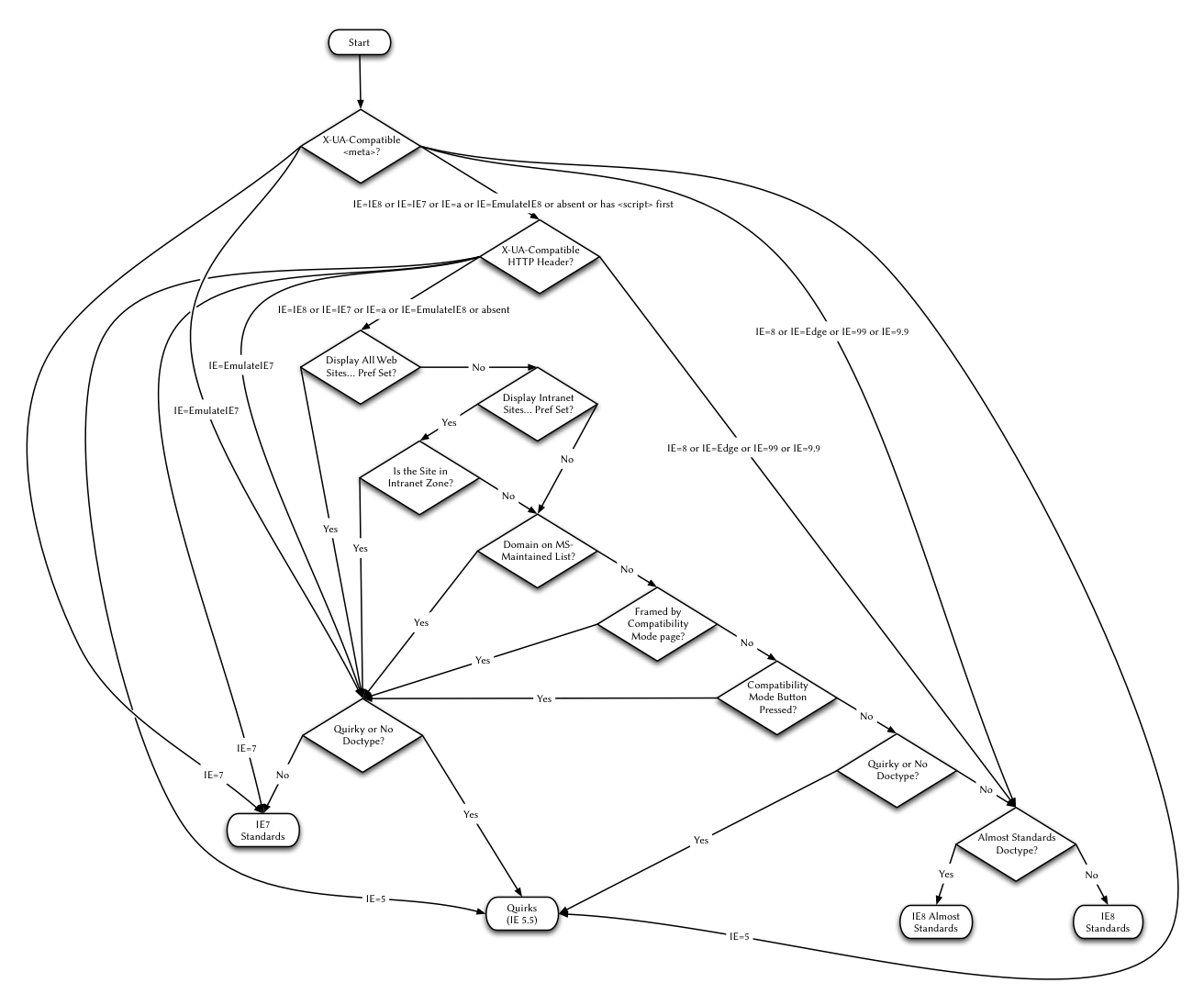
Вы должны прочитать остальные статьи Хенри, потому что я привел здесь всё упрощённо. Даже в IE5/Mac было несколько вариантов доктайпа. Со временем список особенностей браузеров вырос и вместе с ним увеличился список доктайпов, которые переключают в режим совместимости. В последний раз, когда я занимался подсчётом, было 5 доктайпов для переключения в «почти стандартный режим» и 73 для переключения в «режим совместимости». Вероятно, при этом я пропустил несколько и я ещё молчу про ту сумасшедшую фигню, что делает Internet Explorer 8 для переключения между четырьмя (четырьмя!) режимами отображения. Вот схема. Убейте ее! Убейте и сожгите!
{kind=link}
Так, где мы? Ах, да, доктайп.
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
Если вам нравится этот доктайп, можете оставить его. Или можете изменить доктайп на HTML5, который короче и приятнее, к тому же переключает в «стандартный режим» во всех современных браузерах.
Вот HTML5 доктайп.
<!DOCTYPE html>
Вот и все. Всего 15 символов. Это так просто, что вы можете набрать его вручную и не выкручиваться.
Корневой элемент
 HTML-страница — это набор вложенных элементов, по своей структуре напоминающей дерево. Некоторые элементы являются «родственными», подобно ветвям, выходящим из одного ствола. Другие элементы «дочерние» для других элементов, как маленькая ветвь, растущая из большой ветки. Это правило работает и в обратную сторону — элемент, непосредственно содержащий другие элементы, называется «родительским», и «предком» для «внучатых» элементов. Элемент, не имеющий дочерних элементов, называется узлом. Самый главный элемент, который выступает предком для всех остальных, зовется «корневым». В HTML-документе корневым всегда является <html>.
HTML-страница — это набор вложенных элементов, по своей структуре напоминающей дерево. Некоторые элементы являются «родственными», подобно ветвям, выходящим из одного ствола. Другие элементы «дочерние» для других элементов, как маленькая ветвь, растущая из большой ветки. Это правило работает и в обратную сторону — элемент, непосредственно содержащий другие элементы, называется «родительским», и «предком» для «внучатых» элементов. Элемент, не имеющий дочерних элементов, называется узлом. Самый главный элемент, который выступает предком для всех остальных, зовется «корневым». В HTML-документе корневым всегда является <html>.
Корневой элемент может выглядеть так.
<html xmlns="http://www.w3.org/1999/xhtml"
lang="ru"
xml:lang="ru">
Ничего плохого в этом коде нет, так что если он вам нравится, можете его оставить, в HTML5 он абсолютно корректен. Но некоторые части уже не требуются, поэтому можно удалить их, тем самым сэкономив несколько байт.
Первое, что нужно обговорить, это атрибут xmlns, который остался от XHTML. Этот атрибут сообщает, что элементы на этой странице находятся в пространстве имен XHTML, описанному по адресу http://www.w3c.org/1999/xhtml. Однако элементы HTML5 и так находятся в этом пространстве имен, так что нет необходимости объявлять это намеренно. Страница HTML5 будет работать одинаково во всех браузерах, независимо от того, присутствует атрибут xmlns или нет.
После удаления xmlns останется следующее:
<html lang="ru" xml:lang="ru">
Два атрибута, lang и xml:lang оба определяют язык текущей веб-страницы. Значение ru обозначает русский язык, его можно поменять на другой код языка. Почему используется два атрибута для одного и того же? Опять же, это наследие XHTML. В HTML5 только атрибут lang дает какой-либо эффект. Вы можете оставить xml:lang при желании, но тогда нужно убедиться, что он содержит то же значение, что и lang.
Готовы к выбрасыванию? Если да, то поехали. Едем, едем... приехали. Вот что осталось от нашего корневого элемента.
<html lang="ru">
И это все, что я хотел сказать об этом.
Элемент <head>

Первый дочерний элемент в корне это, как правило, тег <head>. Элемент <head> содержит метаданные — информацию о странице, но не тело самой страницы, которое располагается в <body>. Сам элемент <head> довольно скучен и не изменился на интересный вариант в HTML5.
Хорошие вещи находятся внутри <head>. И для их изучения обратимся к нашему примеру.
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Мой блог</title>
<link rel="stylesheet" type="text/css" href="style/style-original.css" />
<link rel="alternate" type="application/rss+xml"
title="Фид моего блога"
href="/rss.xml" />
<link rel="search" type="application/opensearchdescription+xml"
title="Поиск по блогу"
href="/sites/search/search.xml" />
<link rel="shortcut icon" href="/favicon.ico" />
</head>
Вначале тег <meta>.
Кодировка символов
Когда вы думаете «текст», вы, вероятно, думаете о «знаках и символах, что я вижу на экране моего компьютера». Но компьютерам нет дела до знаков и символов, они имеют дело с битами и байтами. Каждый фрагмент текста, который вы когда-либо видели на экране компьютера, на самом деле хранится в определенной кодировке. Существуют сотни различных кодировок символов, некоторые из них оптимизированы для конкретных языков, таких как русский, китайский или английский, другие могут быть использованы сразу для нескольких языков. Грубо говоря, кодировка символов обеспечивает перевод между тем, что вы видите экране и тем, что компьютер хранит в памяти и на диске.
В действительности, все гораздо сложнее. Некоторые символы могут быть более чем в одной кодировке, каждая кодировка может использовать разные последовательности байтов в зависимости от способа хранения символов. Таким образом, кодировка это своего рода ключ для расшифровки текста. Всякий раз, когда кто-то дает вам последовательность байтов и утверждает что это «текст», вы должны знать, какую кодировку символов они использовали, чтобы суметь перевести байты в символы и вывести их.
Как же фактически ваш браузер определяет кодировку набора байтов, что посылает веб-сервер? Рад, что спросили. Если вы знакомы с HTTP-заголовками, то возможно видели подобный.
Content-Type: text/html; charset="utf-8"
Эта строка говорит, что веб-сервер считает, что посылает вам HTML-документ в кодировке UTF-8. К сожалению, в Интернете творится каша — некоторые авторы могут контролировать HTTP-сервер, другие же нет. К примеру, сайт blogger.com может содержать различный контент предоставленный разными людьми, но управляется серверами Google. В HTML4 используется способ указания кодировки самостоятельно в любом HTML-документе. Вы, наверное, встречали такую строку.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Эта строка говорит о том, что автор считает, что в HTML-документе применяется кодировка UTF-8.
Обе указанные техники работают в HTML5. Использование HTTP-заголовка является предпочтительным методом, и он перекрывает тег <meta>, если таковой имеется. Но не каждый может установить HTTP-заголовки, так что метатеги все еще применяются. К тому же он стал намного проще в HTML5. Теперь это выглядит так.
<meta charset="utf-8" />
Это работает во всех браузерах. Выбор этого атрибута продиктован тем, что он уже реализован в браузерах, к тому же люди часто оставляли значение без кавычек.
<META HTTP-EQUIV=Content-Type CONTENT=text/html; charset=ISO-8859-1>
Спроси профессора Маркапа
☞В. Я никогда не использую смешные символы. Надо ли мне объявлять мою кодировку?
О. Да, вы всегда должны указывать кодировку на каждой веб-странице. Отсутствие кодировки может привести к уязвимости системы безопасности.
Подведем итоги. Вы должны всегда указывать кодировку во всех HTML-документах, иначе могут произойти неприятные вещи. Вы можете сделать это через HTTP-заголовки, написанием <meta http-equiv> или укороченное <meta charset>, но пожалуйста, сделайте это. Веб будет вам благодарен.
Дружеские отношения
Обычные ссылки всего лишь указатель на другой сайт. Отношения между ссылками это способ пояснить, почему вы указываете на другую страницу. Вот окончания предложения «Потому что...».
- ...это таблица стилей, содержащая правила CSS, которые браузер должен применить к документу.
- ...это фид, содержащий некоторый контент, как эта страница, но в специальном формате.
- ...это перевод страницы на другой язык.
- ...это следующий раздел онлайновой книги.
И так далее. HTML5 разделяет отношения ссылок на две категории, которые могут быть созданы с помощью тега <link>. Ссылки на внешние ресурсы для расширения текущего документа и гипертекстовые ссылки на другие документы.
Поведение ссылки на внешние ресурсы зависит от отношения, которое определено для соответствующего типа ссылки.
В примере, что я приводил ранее, только первая ссылка (rel="stylesheet") указывает на внешний ресурс. Остальные являются гиперссылками на другие документы. Вы можете при желании пройти по этим ссылкам, но они не требуются для просмотра текущей страницы.
Чаще всего отношения ссылок видны в теге <link> раздела <head>. Некоторые отношения также могут быть использованы для тега <a>, но это встречается довольно редко, даже когда допускается. HTML5 также позволяет включить некоторые отношения для <area>, но это еще реже используется (HTML4 не разрешает атрибут rel для тега <area>). Посмотрите полную диаграмму для проверки, где вы можете использовать значение rel.
Спроси профессора Маркапа
☞В. Могу я создать свои собственные отношения между ссылками?
О. Кажется, имеется бесконечный запас идей для новых отношений между ссылками. В попытках помешать людям творить фигню WHATWG (Web Hypertext Application Technology Working Group, Рабочая группа по прикладным веб-технологиям) ведет реестр предложенных значений rel и устанавливает процесс их принятия.
rel="stylesheet"
Давайте посмотрим на первую ссылку в нашем примере.
<link rel="stylesheet" href="style/style-original.css" type="text/css" />
Это наиболее встречаемое отношение ссылок в мире (в буквальном смысле). Строка <link rel="stylesheet"> указывает на CSS-правила, которые хранятся в отдельном файле. Одну небольшую оптимизацию можно сделать в HTML5 и убрать атрибут type. В нем только один язык стилей, CSS, и он установлен по умолчанию. Это работает во всех браузерах. Думаю, кто-то может придумать когда-нибудь новый язык стилей, но если это произойдет, просто добавьте атрибут type обратно.
<link rel="stylesheet" href="style/style-original.css" />
rel="alternate"
Вернемся к нашей странице.
<link rel="alternate" type="application/rss+xml"
title="Фид моего блога"
href="/feed/" />
Эти отношения ссылок также весьма распространены. <link rel="alternate"> в сочетании с типом RSS или Atom в атрибуте type позволяет то, что называется «автоматическое обнаружение канала». Это позволяет собирать фид читалками (вроде Google Reader) для получения с сайта последних новостей. Большинство браузеров также поддерживает автоматическое обнаружение фида, показывая специальный значок рядом с адресом сайта. В отличие от rel="stylesheet", атрибут type здесь важен. Не удаляйте его!
Ссылка с отношением rel="alternate" всегда была странным гибридом в использовании, даже в HTML4. В HTML5 ее определение было уточнено и расширено, чтобы более точно описать существующий контент. Как вы видели, использование rel="alternate" в сочетании с type=application/atom+xml указывает на Atom-фид для текущей страницы. Но вы также можете использовать rel="alternate" в сочетании с другими значениями type для обозначения того же содержания в другой формат, например PDF.
HTML5 также отправляет на отдых давнюю путаницу о том, как делать ссылку на переводы документов. HTML 4 говорит использовать атрибут lang в сочетании с rel="alternate" для указания языка связанного документа, но это некорректно. В списке исправлений HTML4 перечислены четыре ошибки спецификации. Одна из этих ошибок связана с заданием языка документа через rel="alternate". Правильный способ, описанный в исправлениях HTML4 и применяемый в HTML5, заключается в использовании атрибута hreflang. К сожалению, эти исправления не были повторно включены в спецификацию HTML 4, потому что никто больше в Рабочей группе по HTML не работает над ней.
Другие отношения ссылок в HTML5
rel="archives" указывает, что ссылка описывает набор записей, документов или других материалов, представляющих исторический интерес. Главная страница блога может содержать ссылку на список старых сообщений с указанием rel="archives".
rel="author" используется для ссылки на страницу с информацией об авторе. Это может быть почтовый адрес, хотя и не обязательно. Обычно это ссылка на контактную информацию или страницу «Об авторе».

Запись rel="external" сообщает, что ссылка ведет на документ, который не является частью сайта. Я считаю, что ее впервые популяризировал WordPress, когда использовал в ссылках комментариев.
HTML4 включает rel="start", rel="prev" и rel="next" для определения отношений между страницами, которые являются частью серии (например, разделы книги или даже сообщения в блоге). При этом корректно использовалась только запись rel="next". Люди вставляли rel="previous" вместо rel="prev", вставляли rel="begin" и rel="first" вместо rel="start", использовали rel="end" вместо rel="last". И ох, самостоятельно делали rel="up" для указания на «родительскую» страницу.
HTML5 включает rel="first" как наиболее распространенный вариант разных способов сказать «первая страница в серии» (rel="start" не является синонимом и оставлен для обратной совместимости). Еще добавлены rel="prev" и rel="next" как в HTML4, rel="previous" для обратной совместимости, а также rel="last" (последняя страница в серии, зеркальный к rel="first") и rel="up".
Лучший способ подумать о rel="up" это посмотреть на навигацию в виде хлебных крошек (или представить ее). Главная страница это первая страница в навигации, а текущая страница находится в хвосте. rel="up" указывает на страницу, следующую за последней в хлебных крошках.
rel="icon" является вторым по популярности отношением между ссылками после rel="stylesheet". Оно обычно используется вместе с иконкой сайта, вот так.
<link rel="shortcut icon" href="/favicon.ico">
Все основные браузеры поддерживают такое связывание иконки со страницей. Обычно она отображается в адресной строке браузера рядом с URL или во вкладке браузера или в том и другом месте.
Новое в HTML5: атрибут sizes может быть использован для указания размера иконки.
rel="license" был включен сообществом по микроформатам. Такое отношение означает, что ссылка ведет на страницу с авторскими правами, согласно которым предоставляется текущий документ.
rel="nofollow" указывает, что ссылка не одобрена автором или издателем страницы или что ссылка на указанный документ включена в основном из-за коммерческих отношений между людьми связанных с этими страницами. Это отношение было изобретено в Google и стандартизировано в сообществе по микроформатам. WordPress вставляет rel="nofollow" в ссылки, добавленные в комментариях, полагая, что раз ссылки с nofollow не передают PageRank, то спамеры откажутся постить спам в комментариях блога. Этого не произошло, но rel="nofollow" остался.
rel="noreferrer" указывает, что информация о реферере не должна утекать при переходе по ссылке. Браузеры не поддерживают это отношение, однако оно недавно было добавлено в браузерный движок Webkit и в конечном итоге появится в Safari, Chrome и других браузерах, основанных на этом движке.

rel="pingback" указывает адрес пингбэк-сервера. Как поясняется в спецификации, «пингбэк» это способ для блога автоматически оповещать сайты, ссылающиеся на него. Это создает обратную связь — способ пройти назад по цепочке ссылок вместо «прямого прохода». В блогах, частности WordPress, пингбэк-механизм используется для уведомления авторов, что вы ссылаетесь на кого-то при создании новой записи.
rel="prefetch" сообщает, что превентивная выборка и кэширование указанного ресурса, вероятно, будет полезна и скорее всего пользователю понадобится этот ресурс. Поисковые системы иногда добавляют <link rel="prefetch" href="URL верхних результатов"> на страницу результатов поиска, если они полагают, что верхние результаты более популярны других. Посмотрите исходный код результатов поиска Google для CNN через Firefox и сделайте поиск по ключевому слову prefetch. Mozilla Firefox является пока единственным браузером, поддерживающим rel="prefetch".
rel="search" говорит, что ссылаемый документ содержит интерфейс поиска и связанных с ним ресурсов. Так, если вы хотите полезно использовать rel="search", укажите на OpenSearch-документ, который описывает, как браузер может формировать адреса для поиска ключевых слов по текущему сайту. Формат OpenSearch поддерживается браузером Internet Explorer начиная с версии 7.0 и Mozilla Firefox с версии 2.0.
rel="sidebar" показывает, что ссылаемый документ, если это возможно, будет показан в дополнительном контексте браузера. Что это значит? В Opera и Firefox это реализовано так: когда я щелкаю по ссылке, открывается окно для добавления ссылки в панель закладок. Internet Explorer, Safari и Chrome игнорируют rel="sidebar" и покажут обычную ссылку.
rel="tag" сообщает, что метка непосредственно связана с текущим документом. Понятие «метка» (теги, категории) было придумано компанией Technorati для помощи в систематизации постов блога. Ранее блоги и руководства и называли их «метки Technorati». Вы правильно поняли: коммерческая компания убедила весь мир добавить метаданные, которые сделают труд компании проще. Прекрасная работа! Синтаксис позже был стандартизирован сообществом по микроформатам, где его просто назвали rel="tag". В большинстве систем блогов, которые позволяют связывать категории, ключевые слова или метки с постами, ссылки маркируются через rel="tag". Браузеры ничего особого с такими ссылками не делают, поскольку они в действительности предназначены для поисковых систем.
Новые семантические элементы в HTML5
HTML5 не просто делает существующую разметку компактнее, он также определяет новые семантические элементы.
| <section> | Элемент <section> определяет основной документ или раздел приложения. В данном контексте это тематическая группировка содержания, как правило, с заголовком. Например, разделами могут быть главы, вкладки в диалоговом окне с вкладками или пронумерованные разделы диссертации. Главная страница веб-сайта может быть разбита на разделы для вступления, вывода новостей, контактной информации. |
| <nav> | Элемент <nav> представляет собой раздел навигационных ссылок, содержащий ссылки на другие страницы. Не все группы ссылок должны заключаться в тег <nav> — только разделы, состоящие из основных блоков навигации. В частности, в подвале страницы часто содержится краткий список ссылок, таких как: условия обслуживания, главная страница, страница с авторскими правами. Для подобных случаев вполне достаточно тега <footer>, без использования <nav>. |
| <article> | Элемент <article> задает компонент страницы, предназначенный для самостоятельного распространения или повторного использования, например в синдикации. Это может быть сообщение форума, журнальная или газетная статья, запись в блоге, пользовательский комментарий, интерактивный виджет, гаджет или любой другой независимый контент. |
| <aside> | Этот элемент представляет раздел страницы, имеющий косвенное отношение к содержанию и который можно отделить от контента. В полиграфии такие участки часто выделяют плашкой. Тег <aside> может быть использован для вывода цитат, боковых панелей, рекламы, навигации через <nav> и другого контента, который считается отдельным от основного содержания страницы. |
| <hgroup> | Элемент <hgroup> задает заголовок раздела и применяется для группирования нескольких тегов <h1>–<h6>, когда заголовок включает несколько уровней, таких как подзаголовки, альтернативные названия или лозунги. |
| <header> | Представляет собой группу из вступительных или навигационных средств. Элемент <header> обычно содержит заголовок раздела (теги <h1>–<h6> или <hgroup>), но это не обязательно. <header> также может быть использован для обертывания раздела содержания, формы поиска, или соответствующих логотипов. |
| <footer> | Задает нижний колонтитул для раздела содержания или подвал для страницы. Элемент <footer> обычно содержит информацию о разделе, такую как: имя автора, ссылки на соответствующие документы, авторские данные и тому подобное. Колонтитулы не обязательно должны выводиться в конце раздела, как это обычно делается. |
| <time> | Представляет собой либо время в 24-часовом формате, либо точную дату, которую при желании можно совмещать со временем и указанием часового пояса. |
| <mark> | Помечает фрагмент документа или выделяет его в справочных целях. |
Я знаю, вам не терпится вначале опробовать эти новые элементы, иначе вы бы не читали эту главу. Но прежде мы должны сделать небольшой крюк.
Длинное отступление о том, как браузеры обрабатывают неизвестные элементы
Каждый браузер имеет основной список HTML-элементов, которые он поддерживает. Например, список элементов Mozilla Firefox хранит в nsElementTable.cpp. Элементы вне этого списка рассматриваются как «неизвестные». Вот две главные проблемы, связанные с такими элементами.
- Как должен быть стилизован элемент? По умолчанию <p> имеет отступ от верхнего и нижнего края, <blockquote> отступ от левого края, <h1> отображается крупным шрифтом. Но какой стиль по умолчанию должен применяться к неизвестным элементам?
- Как элемент должен выглядеть в DOM? Файл nsElementTable.cpp хранит информацию, какие элементы могут содержать в себе другие. Если вы написали <p><p>, второй элемент неявно закрывает первый, так что они являются элементами одного уровня, а не родителем и потомком. Но если вы пишете <p><span>, то <span> не закрывает <p> потому что Firefox знает, что <p> это блочный элемент, который может содержать встроенные элементы <span>. Так что <span> в DOM обозначается как дочерний для <p>.
Различные браузеры отвечают на эти вопросы по-разному. Вы в шоке, я знаю. Из основных браузеров Microsoft Internet Explorer имеет больше всех проблем, но и остальные браузеры нуждаются в небольшой помощи.
На первый вопрос есть относительно простой ответ: к неизвестным элементам вообще не надо применять стили. В действительности они наследуют свойства CSS там, где это возможно, автор же добавляет остальной требуемый ему стиль через CSS. В основном это работает, но есть один маленький глюк, который нужно знать.
Профессор Маркап говорит
☞Все браузеры отображают неизвестные элементы как встроенные, т.е. так, словно в стилях к ним добавили display: inline.
Есть несколько новых элементов, определенных в HTML5 как блочные. При этом они могут содержать другие блочные элементы, и HTML5-совместимые браузеры будут добавлять к ним display: block. Если вы хотите использовать эти элементы в старых браузерах, вам нужно задать стиль для них вручную. Вот код взятый из статьи Ричи Кларка HTML5 Reset Stylesheet, где написано много других вещей выходящих за рамки этой главы.
article,aside,details,figcaption,figure,
footer,header,hgroup,menu,nav,section {
display:block;
}
Но погодите, все еще хуже! До версии 9.0, Internet Explorer не применяет любые стили к неизвестным элементам. Например, если у вас вот такая разметка.
<style type="text/css">
article { display: block; border: 1px solid red; }
</style>
...
<article>
<h1>Добро пожаловать в Инитех</h1>
<p>Это ваш <span>первый день</span>.</p>
</article>
Internet Explorer до версии 8.0 включительно не будет рассматривать тег <article> как блочный и не покажет красную рамку вокруг статьи. Все стилевые правила просто игнорируются. Когда я писал эту главу, Internet Explorer 9 еще находился в стадии разработки, но Майкрософт заявил (и разработчики проверили), что в Internet Explorer 9 не будет этой проблемы.
Для иллюстрации различий приведен ASCII-рисунок показывающий DOM предписанный для HTML5.
article | +--h1 (дочерний к article) | | | +--текст "Добро пожаловать в Инитех" | +--p (дочерний к article, родственный h1) | +--текст "Это ваш " | +--span | | | +--текст "первый день" | +--текст "."
В действительности Internet Explorer создает следующий DOM.
article (без дочерних элементов) h1 (родственный article) | +--текст "Добро пожаловать в Инитех" p (родственный of h1) | +--текст "Это ваш " | +--span | | | +--текст "первый день" | +--текст "."
Существует способ обойти эту чудную проблему. Если предварительно создать фиктивный тег <article> через JavaScript, то Internet Explorer волшебным образом признает элемент <article> и позволит добавлять к нему CSS. Нет нужды вставлять фиктивный элемент в DOM. Простого однократного создания элемента достаточно, чтобы научить IE стилизации элемента, который он не признает.
<html>
<head>
<style>
article { display: block; border: 1px solid red }
</style>
<script>document.createElement("article");</script>
</head>
<body>
<article>
<h1>Welcome to Initech</h1>
<p>This is your <span>first day</span>.</p>
</article>
</body>
</html>
Это работает во всех версиях Internet Explorer, включая IE 6! Мы можем расширить эту технику, чтобы сразу создать фиктивные копии всех новых элементов HTML5 — опять же, они никогда не вставляются в DOM, так что вы их не увидите. Иначе пришлось бы беспокоиться о браузерах, не поддерживающих HTML5.
Реми Шарп написал скрипт с именем HTML5 enabling script. Скрипт прошел уже 14 версий со времени написания, но вот его основная идея.
<!--[if lt IE 9]>
<script>
var e = ("abbr,article,aside,audio,canvas,datalist,details," +
"figure,footer,header,hgroup,mark,menu,meter,nav,output," +
"progress,section,time,video").split(',');
for (var i = 0; i < e.length; i++) {
document.createElement(e[i]);
}
</script>
<![endif]-->
Фрагмент <!--[if lt IE 9]> and <![endif]--> называется условным комментарием. Internet Explorer интерпретирует его как установку: «если текущий браузер Internet Explorer и версии ниже 9, то выполнить этот блок». Любой другой браузер будет рассматривать весь блок как комментарий HTML. Конечным результатом является то, что Internet Explorer до версии 8.0 включительно будет выполнять этот скрипт, а другие браузеры целиком его игнорировать. Это позволяет страницам загружаться быстрее в тех браузерах, что не поддерживают данный хак.
Код JavaScript относительно простой. В переменной e хранится массив строк вроде «abbr», «article», «aside» и др. Затем в цикле обходим этот массив и создаем каждый элемент через document.createElement(). Так как мы игнорируем возвращаемое значение, элементы не добавляются в DOM. Этого достаточно, чтобы заставить Internet Explorer обрабатывать эти элементы так, как нам надо, чтобы использовать их позже на странице.
Это «позже» имеет большое значение. Скрипт должен располагаться в верхней части страницы, предпочтительно внутри <head>, а не внизу. Таким образом, Internet Explorer будет выполнять скрипт прежде, чем он разберет теги и атрибуты. Если вы вставите скрипт в нижнюю часть страницы, будет слишком поздно. Internet Explorer уже получит неправильную разметку и построит ошибочный DOM и уже нельзя будет повернуть назад и настроить все заново.
Реми Шарп уменьшил скрипт и разместил его на Google Project Hosting. Там находится сам код скрипта и MIT-лицензия, так что вы можете использовать его в любом проекте. Если хотите, можете сделать ссылку на последнюю версию скрипта напрямую, как показано ниже.
<head>
<meta charset="utf-8" />
<title>Мой блог</title>
<!--[if lt IE 9]>
<script src="http://html5shiv.googlecode.com/svn/trunk/html5.js"></script>
<![endif]-->
</head>
Теперь мы готовы начать использовать новые семантические элементы HTML5.
Заголовки
Вернемся к нашему примеру. В частности, посмотрим только на заголовки.
<div id="header">
<h1>Мой блог</h1>
<p class="tagline">Много усилий пошло на создание этих усилий</p>
</div>
...
<div class="entry">
<h2>День путешествия</h2>
</div>
...
<div class="entry">
<h2>Я уехал в Прагу!</h2>
</div>
Ничего плохого в этой разметке нет, если она вам нравится, можете ее оставить, это валидный HTML5. Но HTML5 предоставляет некоторые дополнительные семантические элементы для заголовков и разделов.
Во-первых, давайте избавимся от <div id="header">. Хотя это типовой шаблон, он ничего не значит. Для тега <div> не задана семантика, атрибут id тоже не несет определенного смысла. Браузеры не могут сделать какой-либо вывод на основе значения id. Вы можете заменить строку на <div id="shazbot"> и у нее останется такое же семантическое значение, т.е. никакое.
В HTML5 для этих целей определен элемент <header>. Вот как это будет выглядеть на странице нашего примера.
<header>
<h1>Мой блог</h1>
<p class="tagline">Много усилий пошло на создание этих усилий</p>
...
</header>
Это хорошо. Страница рассказывает желающим, что это заголовок. Но что делать со слоганом, еще одним типовым элементом, для которого нет стандартного тега? Это трудный выбор, как его маркировать. Слоган вроде бы подзаголовок, но «привязан» к основному заголовку. То есть, это подзаголовок, но не имеющий собственного раздела.
Теги заголовков, такие как <h1> и <h2> формируют структуру вашей страницы. Собранные воедино они создают иерархию, которую можно использовать для визуализации страницы или навигации по ней. Экранные ридеры используют схему документа, чтобы помочь слепым пользователям перемещаться по странице. Есть онлайн-инструмены и расширения браузера, которые также могут помочь вам представить схему вашего документа.
В HTML4 элементы <h1>–<h6> были единственным способом создания схемы документа, например, такой.
Мой блог (h1) | +--День путешествия (h2) | +--Я в Праге! (h2)
Прекрасно, но это означает, что нет никакого способа для разметки слогана «Много усилий пошло на создание этих усилий». Если мы попытемся отметить его как <h2>, то добавится фантомный узел в схему документа.
Мой блог (h1) | +--Много усилий пошло на создание этих усилий (h2) | +--День путешествия (h2) | +--Я в Праге! (h2)
Может быть, мы могли бы отметить слоган как <h2>, а каждый заголовок статьи как <h3>? Нет, это еще хуже.
Мой блог (h1) | +--Много усилий пошло на создание этих усилий (h2) | +--День путешествия (h3) | +--Я в Праге! (h3)
У нас все еще есть фантомный узел в схеме документа, но он «украл» детей, которые по праву принадлежат корневому узлу. В этом и заключается проблема: HTML4 не предоставляет способ разметки подзаголовка без добавления его в схему документа. Независимо от наших перестановок, «Много усилий пошло на создание этих усилий» будет в конечном итоге в этом графе. Именно поэтому мы остановились на семантически бессмысленной разметке вроде <p class="tagline">.
HTML5 предоставляет решение — элемент <hgroup>. Он используется в качестве обрамления для двух или более связанных элементов заголовка. Что значит «связанных»? Лишь то, что взятые вместе они создают один узел в схеме документа.
Возьмем эту разметку.
<header>
<hgroup>
<h1>Мой блог</h1>
<h2>Много усилий пошло на создание этих усилий</h2>
</hgroup>
...
</header>
...
<div class="entry">
<h2>День путешествия</h2>
</div>
...
<div class="entry">
<h2>Я в Праге!</h2>
</div>
Созданная схема документа.
Мой блог (h1 и hgroup) | +--День путешествия (h2) | +--Я в Праге! (h2)
Вы можете проверить ваши страницы через HTML5 Outliner чтобы убедиться, что вы используете заголовки правильно.
Статьи
Вновь обратимся к нашему примеру и посмотрим, что можно сделать с этим кодом.
<div class="entry">
<p class="post-date">Октябрь 22, 2009</p>
<h2>
<a href="#"
rel="bookmark"
title="ссылка на этот пост">
День путешествия
</a>
</h2>
...
</div>
Опять же, это валидный HTML5. Но HTML5 включает специфичный элемент для общего случая разметки статьи на странице — метко названный <article>.
<article>
<p class="post-date">Октябрь 22, 2009</p>
<h2>
<a href="#"
rel="bookmark"
title="ссылка на этот пост">
День путешествия
</a>
</h2>
...
</article>
Ах, не все так просто. Существует еще одно изменение, которое вы должны сделать. Вначале я покажу, а потом объясню его.
<article>
<header>
<p class="post-date">Октябрь 22, 2009</p>
<h1>
<a href="#"
rel="bookmark"
title="ссылка на этот пост">
День путешествия
</a>
</h1>
</header>
...
</article>
Уловили, да? Я заменил <h2> на <h1> и обернул его элементом <header>. Вы уже видели <header> в действии. Он выступает контейнером для всех элементов образующих заголовок статьи (в данном случае это дата публикации статьи и ее название). Но... но... но... разве не должен быть только один <h1> на страницу? Не испортит ли это схему документа? Нет, но чтобы понять это мы должны вернуться на шаг назад.
В HTML 4 единственным путем формирования схемы документа было использование <h1>–<h6>. Если вы хотели иметь лишь один корневой узел в схеме, то должны были ограничиться одним <h1>. Но спецификация HTML5 устанавливает алгоритм генерации схемы документа, включающий в себя новые семантические элементы. Этот алгоритм говорит, что <article> создает новый раздел, иными словами, новый узел в схеме документа. А в HTML5 каждый раздел может содержать собственный тег <h1>.
Это довольно сильное отличие от HTML4 и вот почему оно замечательно. Многие веб-страницы в действительности формируются шаблонно. Кусок взят из одного источника, кусок из другого и вставлен в код. Многие учебники поощряют этот путь — «Вот HTML-код, скопируйте его и вставьте к себе на страницу». Это хорошо для небольших фрагментов, но что если вы вставите целый раздел? В этом случае, в учебнике можно прочесть нечто вроде «Вот HTML-код, скопируйте его, вставьте в текстовый редактор и поправьте заголовки, чтобы они соответствовали уровню вложенности в вашей странице».
Зайду с другой стороны. В HTML4 нет универсального элемента для заголовков. Есть шесть строго пронумерованных тегов <h1>–<h6>, которые должны быть вложены в указанном порядке. Это хреново, особенно если ваша страница «сборная», а не «авторская». Эта проблема решается новыми элементами для разделов и правилами для имеющихся заголовков. Если вы используете новые элементы для разделов, я могу дать вам эту разметку.
<article>
<header>
<h1>Заголовок</h1>
</header>
<p>Бла-бла...</p>
</article>
Вы можете скопировать и вставить ее в любом месте вашей страницы без изменений. Тот факт, что код содержит <h1>, не является проблемой из-за контейнера <article>. Этот элемент задает автономный узел в схеме документа, а тег <h1> обеспечивает название узла. Все остальные элементы в других разделах страницы остаются на том же уровне, где они и были до этого.
Профессор Маркап говорит
☞В реальности все немного сложнее, чем я сказал. Новые «явные» элементы разделов (например, <h1> внутри <article>) могут взаимодействовать самым неожиданным образом со старыми «неявными» элементами разделов (<h1>–<h6>). Ваша жизнь будет проще, если вы станете использовать только один подход, но не оба сразу. Если придется на странице включить оба подхода, проверьте результат в HTML5 Outliner и убедитесь, что схема вашего документа осмысленна.
Дата и время

Интересно, не так ли? Конечно, не так интересно как спускаться голышом на лыжах с Эвереста и петь гимн США, но довольно захватывающе, насколько это позволяет семантическая верстка. Продолжим с нашим примером. Я выделил следующую строку.
<div class="entry">
<p class="post-date">Октябрь 22, 2009</p>
<h2>День путешествия</h2>
</div>
Все та же старая история, не правда ли? Для даты публикации статьи нет отдельных семантических элементов, поэтому авторы прибегают к типовым тегам, добавляя к ним свое значение атрибута class. Опять же этот код валиден в HTML5, так что вы не обязаны его менять. Но HTML5 предлагает конкретное решение для этого случая — тег <time>.
<time datetime="2009-10-22" pubdate>Октябрь 22, 2009</time>
У элемента <time> три части:
- машинный шаблон времени;
- понятный для человека текст;
- необязательный атрибут pubdate.
В данном примере атрибут datetime указывает только дату, не время. Формат такой: четыре цифры года, две цифры месяца и две цифры дня, разделенные дефисом.
<time datetime="2009-10-22" pubdate>Октябрь 22, 2009</time>
Если вы хотите включить и время, добавьте букву T после даты, затем напишите время в 24-часовом формате и укажите часовой пояс.
<time datetime="2009-10-22T13:59:47+07:00" pubdate>
Октябрь 22, 2009 13:59 Крск
</time>
Заметьте, я изменил и содержание текста — то, что находится между <time> и </time> — в соответствии с машинным шаблоном. На самом деле это не обязательно. Текст может быть любым, главное правильное значение даты/времени в атрибуте datetime. Вот валидный HTML5.
<time datetime="2009-10-22">в четверг</time>
И это тоже валидный HTML5.
<time datetime="2009-10-22"></time>
Последний фрагмент нашей головоломки это атрибут pubdate. Это логический атрибут, поэтому если он вам требуется, просто добавьте его как показано ниже.
<time datetime="2009-10-22" pubdate>Октябрь 22, 2009</time>
Если вам не нравится «голый» атрибут, то есть альтернатива.
<time datetime="2009-10-22" pubdate="pubdate">Октябрь 22, 2009</time>
Что означает pubdate? Одно из двух. Если <time> располагается внутри <article>, то это дата публикации статьи, если <time> не внутри <article>, то это дата публикации всего документа.
Вот как надо изменить статью, чтобы она в полной мере соответствовала HTML5.
<article>
<header>
<time datetime="2009-10-22" pubdate>
Октябрь 22, 2009 </time>
<h1>
<a href="#"
rel="bookmark"
title="ссылка на этот пост">
День путешествия </a>
</h1>
</header>
<p>Lorem ipsum dolor sit amet...</p>
</article>
Навигация
 Одна из наиболее важных частей любого веб-сайта это навигация. На сайте CNN.com вверху каждой страницы имеются вкладки, ссылающиеся на разные новостные разделы сайта: «Entertainment», «Tech», «Travel» и др. У Google на страницах результатов поиска есть аналогичная полоса в верхней части страницы, чтобы опробовать другие службы Google — «Картинки», «Видео», «Карты» и др. В нашем примере страница содержит навигацию в заголовке по разным разделам нашего гипотетического сайта — «главная», «блог», «галерея» и «обо мне».
Одна из наиболее важных частей любого веб-сайта это навигация. На сайте CNN.com вверху каждой страницы имеются вкладки, ссылающиеся на разные новостные разделы сайта: «Entertainment», «Tech», «Travel» и др. У Google на страницах результатов поиска есть аналогичная полоса в верхней части страницы, чтобы опробовать другие службы Google — «Картинки», «Видео», «Карты» и др. В нашем примере страница содержит навигацию в заголовке по разным разделам нашего гипотетического сайта — «главная», «блог», «галерея» и «обо мне».
Вот как панель навигации исходно выглядит.
<div id="nav">
<ul>
<li><a href="#">главная</a></li>
<li><a href="#">блог</a></li>
<li><a href="#">галерея</a></li>
<li><a href="#">обо мне</a></li>
</ul>
</div>
Опять же, это валидный HTML5. Но пока код размечен как список из четырех пунктов, ничего не говорит, что он является частью навигации по сайту. Визуально вы могли бы догадаться, что это часть заголовка страницы и прочитать текст ссылок. Но семантически нет ничего для отличия этого списка ссылок от любого другого.
Кто заботится о семантике навигации? В первую очередь люди с ограниченными возможностями. Почему? Рассмотрим такой сценарий: ваши движения ограничены и пользоваться мышью вам трудно или невозможно. Чтобы компенсировать это, вы можете использовать дополнение браузера, которое позволяет переходить к основным навигационным ссылкам. Или подумайте об этом: если вы плохо видите, можно использовать специальную программу под названием «экранный ридер», которая преобразует текст в речь. Как только вы получите заголовок страницы, следующая важная информация о странице это основные навигационные ссылки. Если вы хотите перейти к ним, то скажете вашему ридеру перепрыгнуть к панели навигации и начать читать. Если вы хотите, можете сказать ридеру пропустить навигацию и начать читать основное содержание. В любом случае, выявленные навигационные ссылки важны программно.
Таким образом, пока нет ничего плохого в использовании <div id="nav"> для разметки навигации по сайту, как и ничего хорошего. В действительности, это затрагивает некоторых людей. HTML5 предоставляет семантический способ разметки навигации по разделам: тег <nav>.
<nav>
<div id="nav">
<ul>
<li><a href="#">главная</a></li>
<li><a href="#">блог</a></li>
<li><a href="#">галерея</a></li>
<li><a href="#">обо мне</a></li>
</ul>
</div>
</nav>
Спроси профессора Маркапа
☞В. Ссылки «пропустить» совместимы с элементом <nav>? Нужны ли такие ссылки в HTML5?
О. Ссылки «пропустить» позволяют ридерам пропускать блоки навигации. Они полезны для пользователей с ограниченными возможностями, которые используют стороннее программное обеспечение для чтения веб-страниц вслух и переходов без мыши.
Некоторые ридеры обновлены для распознавания тега <nav>, пропускают устаревшие ссылки, также они могут автоматически предложить пропустить раздел навигации, обозначенный через <nav>. Однако потребуется какое-то время, прежде чем все пользователи обновят программу своих ридеров, так что вы должны продолжать вставлять собственные ссылки «пропустить» для перескакивания через навигацию.
Подвал
В конце концов, мы подошли к финалу нашего примера. Последняя вещь, о которой я хотел бы сказать это подвал. Оригинальный код подвала такой.
<div id="footer">
<p>§</p>
<p>© 2009 <a href="#">Марк Пилгрим</a></p>
</div>
Это валидный HTML5. Если вам нравится код, оставьте его. Но HTML5 предоставляет для этих целей специальный элемент — <footer>.
<footer>
<p>§</p>
<p>© 2009 <a href="#">Марк Пилгрим</a></p>
</footer>
Что можно поместить в подвал? Наверное то, что вы добавили сейчас в <div id="footer">. Это ответ по кругу, но это действительно так. В спецификации HTML5 говорится: «подвал обычно содержит информацию о разделе, такую как: автор, ссылки на соответствующие документы, авторские данные, и тому подобное». В нашем примере это указание авторского права и ссылка на страницу об авторе. Глядя на некоторые популярные сайты, я вижу большой потенциал у подвала.
- На CNN подвал содержит авторские права, ссылки на переводы, а также ссылки на условия обслуживания, конфиденциальность, страницы «О нас», «Контакты» и «Справка». Все полностью можно добавить в <footer>.
- У Google симпатичная главная страница, внизу ссылки «Рекламные программы», «Решения для предприятий», «Всё о Google»; авторские права, ссылка на политику конфиденциальности. Все это может быть внутри контейнера <footer>.
- В подвале моего блога содержатся ссылки на другие мои сайты плюс авторские права. Определенно подходит для элемента <footer>. Замечу, что ссылки сами по себе не должны оборачиваться элементом <nav>, поскольку это не навигация по сайту, а всего лишь коллекция ссылок на другие мои проекты.
В наше время в моде «толстые подвалы». Посмотрите на сайт W3C. Подвал содержит три столбца, помеченных как «Navigation», «Contact W3C» и «W3C Updates». Код выглядит примерно так.
<div id="w3c_footer">
<div class="w3c_footer-nav">
<h3>Navigation</h3>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/standards/">Standards</a></li>
<li><a href="/participate/">Participate</a></li>
<li><a href="/Consortium/membership">Membership</a></li>
<li><a href="/Consortium/">About W3C</a></li>
</ul>
</div>
<div class="w3c_footer-nav">
<h3>Contact W3C</h3>
<ul>
<li><a href="/Consortium/contact">Contact</a></li>
<li><a href="/Help/">Help and FAQ</a></li>
<li><a href="/Consortium/sup">Donate</a></li>
<li><a href="/Consortium/siteindex">Site Map</a></li>
</ul>
</div>
<div class="w3c_footer-nav">
<h3>W3C Updates</h3>
<ul>
<li><a href="http://twitter.com/W3C">Twitter</a></li>
<li><a href="http://identi.ca/w3c">Identi.ca</a></li>
</ul>
</div>
<p class="copyright">Copyright © 2009 W3C</p>
</div>
Чтобы преобразовать это в семантический HTML5, я хотел бы сделать следующие изменения:
- Преобразовать внешней <id="w3c_footer"> в <footer>.
- Преобразовать два первых <div class="w3c_footer-nav"> в элемент <nav>, а третий в <section>.
- Преобразовать заголовки <h3> в <h1>, так как они теперь будут внутри своего раздела. Элемент <nav> создает раздел в схеме документа подобно элементу <article>.
Окончательный код может выглядеть примерно так.
<footer>
<nav>
<h1>Navigation</h1>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/standards/">Standards</a></li>
<li><a href="/participate/">Participate</a></li>
<li><a href="/Consortium/membership">Membership</a></li>
<li><a href="/Consortium/">About W3C</a></li>
</ul>
</nav>
<nav>
<h1>Contact W3C</h1>
<ul>
<li><a href="/Consortium/contact">Contact</a></li>
<li><a href="/Help/">Help and FAQ</a></li>
<li><a href="/Consortium/sup">Donate</a></li>
<li><a href="/Consortium/siteindex">Site Map</a></li>
</ul>
</nav>
<section>
<h1>W3C Updates</h1>
<ul>
<li><a href="http://twitter.com/W3C">Twitter</a></li>
<li><a href="http://identi.ca/w3c">Identi.ca</a></li>
</ul>
</section>
<p class="copyright">Copyright © 2009 W3C</p>
</footer>
Что еще почитать
Примеры страниц используемых в этой главе:
Как разрешить новые элементы HTML5 в Internet Explorer:
Валидатор HTML5: